.avif)

Explore Manifold's core solutions
.png)

Run complex genomic workflows on your preferred engine without platform switching, enabling seamless transitions between WDL and Nextflow while maintaining consistent interfaces and outputs.
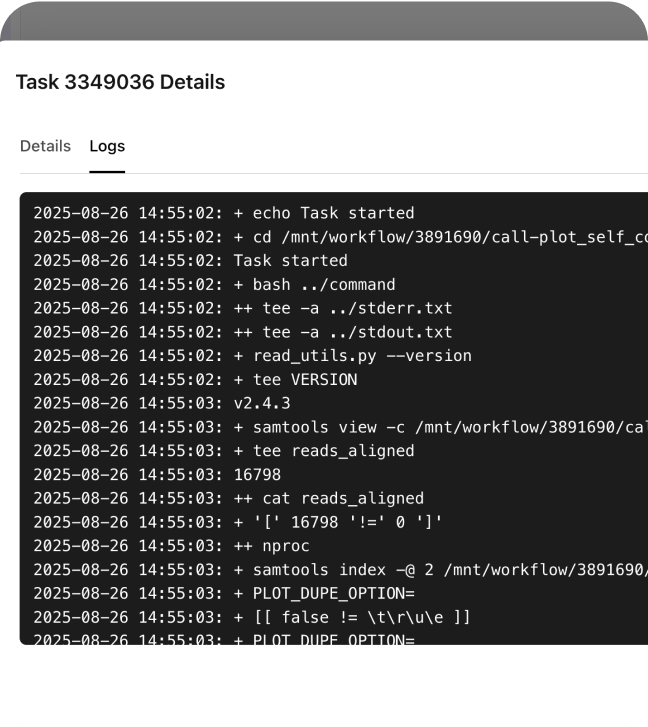
Process petabytes of genomic data reliably with detailed logging, automatic fault recovery, intelligent resource allocation, and sophisticated call caching that eliminates redundant computations.
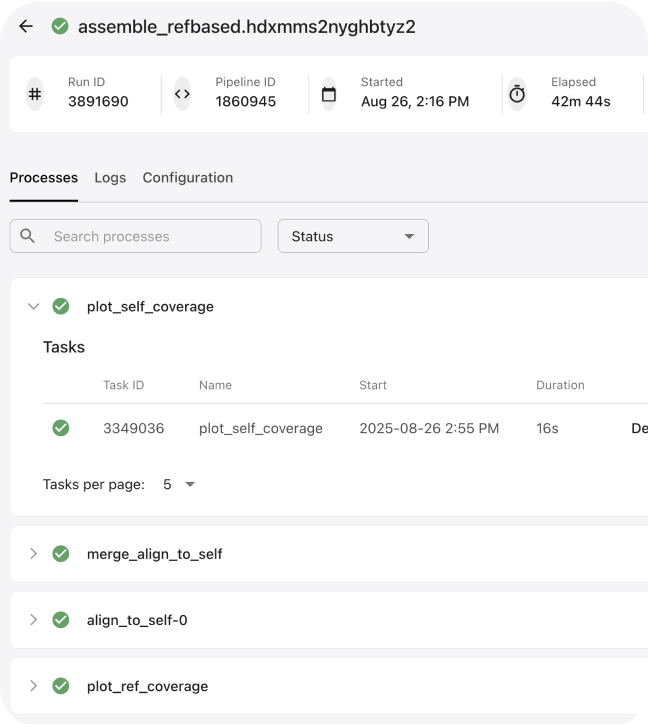
Simplify genomics research with an intuitive interface for configuring community pipelines without programming expertise. Easily adapt published workflows to your specific research needs.
Fit-for-purpose solutions for clinical research leaders in cancer and rare disease.
Streamline legacy systems and manual processes with a single study and data management platform.
Reduce and turnaround time and increase productivity by connecting biospecimen data and clinical data in a single data management platform.
Unify clinical and multimodal data on a modern platform to enable automated data preparation into a research-ready patient model.
Answer research questions about diagnoses, treatments, and outcomes quickly and easily.


Run WDL or Nextflow workflows on AWS HealthOmics or Cromwell without switching platforms or learning new tools.
Scale across thousands of compute nodes to handle petabytes of genomic data with intelligent resource allocation and scatter-gather operations.
Debug at pipeline, task, and individual run levels with centralized logging and live progress tracking for transparent troubleshooting.
Accelerate analyses and reduce costs by leveraging advanced call caching capabilities, which automatically detect and reuse results from previously completed workflow steps—eliminating redundant computations and ensuring efficient, reproducible execution.
Ensure robust fault tolerance with built-in automatic recovery features, which detect failed tasks, retry them intelligently, and resume workflows from the point of interruption—minimizing data loss and manual intervention.
Deploy public workflows with minimal setup—just specify a GitHub repository and Docker image. Our intuitive interface enables point-and-click workflow creation and analysis without coding. Soon, integrated AI agents will guide setup, optimize parameters, and automate routine tasks, making advanced bioinformatics accessible to all.
"At Manifold, AI is the bridge between the language of science and the reality of data, removing barriers so ideas can move at the speed of discovery.”

Sourav Dey, PhD
CPO + Co-founder
Batch Bioinformatics is just one part of the Manifold platform—designed to accelerate every step of your research journey. From AI-assisted data ingestion to to AI-agents for scientific analysis, Manifold helps teams go from raw data to actionable insight without friction.
Request a Demo